
Short Bio
Dongqi Cai (蔡东琪) was an AI Research Scientist at Intel Labs China from 2015 to 2025. She received her Ph.D. from Beijing University of Posts and Telecommunications in 2016, advised by Prof. Fei Su, and subsequently held a joint Postdoctoral Researcher position between Intel and Tsinghua University (THU) from 2017 to 2019, advised by Prof. Li Zhang. Her research focuses on Computer Vision, Deep Learning, and Machine Learning, specifically deep learning based visual recognition, multi-modality visual understanding, and efficient AI application deployment.
Dr. Cai has authored/co-authored impactful research papers in premier conferences including ICML, NeurIPS, CVPR, and ACM ICMI. Notable first-author works include Ske2Grid (ICML 2023) for skeleton-based action recognition and dynamic normalization techniques (NeurIPS 2021) for video action recognition. Her contributions were integral to the winning solutions (1st place in 2017, 2nd place in 2016) for the prestigious EmotiW-AFEW emotion recognition challenges at ACM ICMI. She is also a prolific inventor with over 36 PCT/US patent applications granted/filed as of June 2025, with technologies integrated into Intel products and platforms. She actively serves as a reviewer for top conferences such as NeurIPS and ICML.
Her research and contributions have been recognized through multiple prestigious Intel awards, including the Intel Labs Gordy Award (the highest annual research award named after Intel's co-founder Gordon Earle Moore, 戈登·摩尔奖) in 2016, the Intel China Award in 2017, the Intel China Employee of the Year Award in 2021, and being named a Top Volunteer at Intel Beijing R&D in 2022. She has also been recognized as an Outstanding Party Member within the Zhongzhi Intel Party Branch (2023-2025).
Beyond her technical contributions, Dr. Cai actively serves the Intel community. She is the Leader of the Site Emergency Response Team (ERT) at her Intel location, demonstrating leadership and commitment to workplace safety. She also leads the Intel Badminton Club, fostering employee well-being and team spirit. She serves as a core team member of WIN (Women at Intel Network), advocating for female colleagues' career development and organizing related events. Additionally, she serves as the Organization Committee Member for her Party Branch within Intel, contributing to organizational activities.
Selected Publications
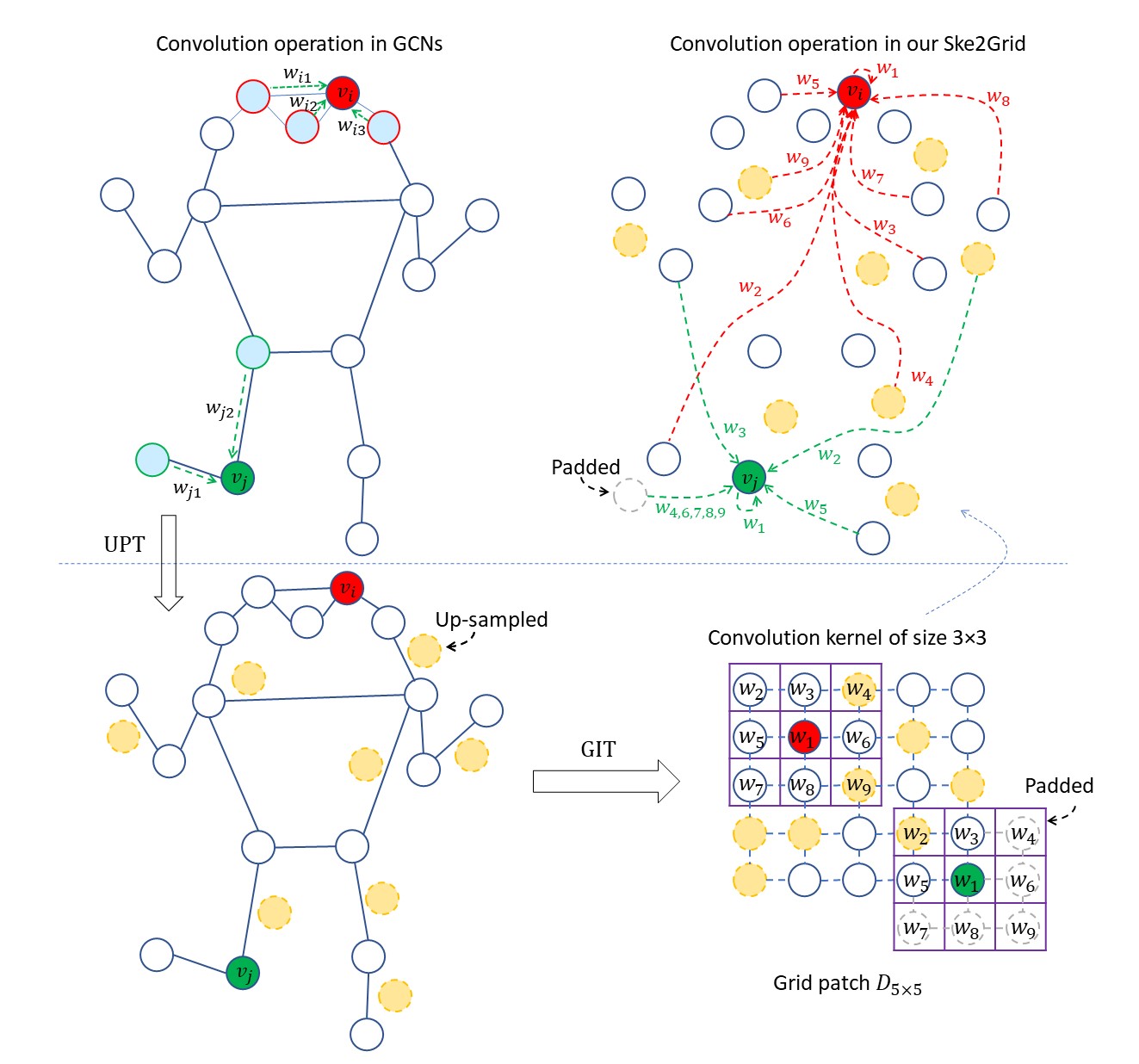
Ske2Grid: Skeleton-to-Grid Representation Learning for Action Recognition
International Conference on Machine Learning (ICML), 2023
Dongqi Cai, YangYuxuan Kang, Anbang Yao, Yurong Chen
This paper presents Ske2Grid, a new representation learning framework for improved skeleton-based action recognition. In Ske2Grid, we define a regular convolution operation upon a novel grid representation of human skeleton, which is a compact image-like grid patch constructed and learned through three novel designs, namely graph-node index transform (GIT), up-sampling transform (UPT) and progressive learning strategy (PLS). We construct networks upon prevailing graph convolution networks and conduct experiments on six mainstream skeleton-based action recognition datasets. Experiments show that our Ske2Grid significantly outperforms existing GCN-based solutions under different benchmark settings, without bells and whistles.
@inproceedings{cai2023ske2grid,
author = {Cai, Dongqi and Kang, Yangyuxuan and Yao, Anbang and Chen, Yurong},
title = {Ske2Grid: Skeleton-to-Grid Representation Learning for Action Recognition},
booktitle = {International Conference on Machine Learning},
year={2023}
url={https://openreview.net/pdf?id=SQtp4uUByd}
}
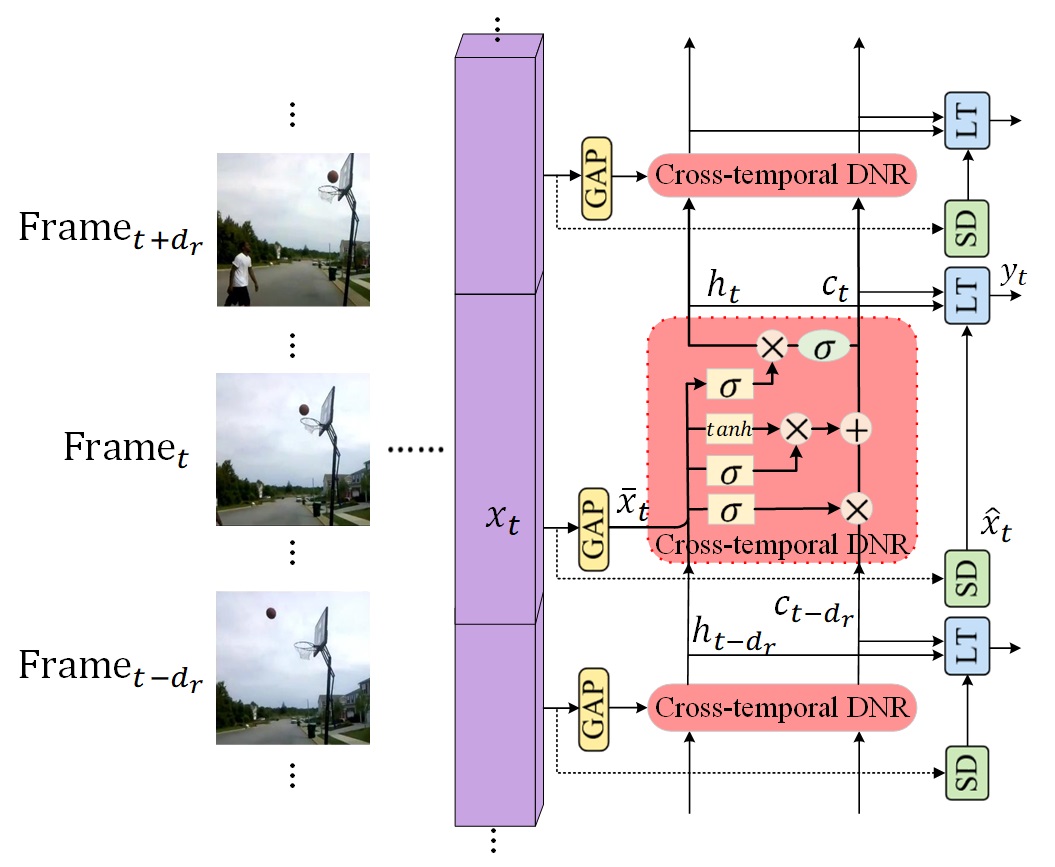
Dynamic Normalization and Relay for Video Action Recognition
Advances in Neural Information Processing Systems (NeurIPS), 2021
Dongqi Cai, Anbang Yao, Yurong Chen
Convolutional Neural Networks (CNNs) have been the dominant model for video action recognition. Due to the huge memory and compute demand, popular action recognition networks need to be trained with small batch sizes, which makes learning discriminative spatial-temporal representations for videos become a challenging problem. In this paper, we present Dynamic Normalization and Relay (DNR), an improved normalization design, to augment the spatial-temporal representation learning of any deep action recognition model, adapting to small batch size training settings. DNR introduces two dynamic normalization relay modules to explore the potentials of cross-temporal and cross-layer feature distribution dependencies for estimating accurate layer-wise normalization parameters. These two DNR modules are instantiated as a light-weight recurrent structure conditioned on the current input features, and the normalization parameters estimated from the neighboring frames based features at the same layer or from the whole video clip based features at the preceding layers. Experimental results show that DNR brings large performance improvements to the baselines, achieving over 4.4% absolute margins in top-1 accuracy without training bells and whistles. More experiments on 3D backbones and several latest 2D spatial-temporal networks further validate its effectiveness.
@inproceedings{cai2021dynamic,
author = {Cai, Dongqi and Yao, Anbang and Chen, Yurong},
title = {Dynamic Normalization and Relay for Video Action Recognition},
booktitle = {Advances in Neural Information Processing Systems},
year={2021}
url={https://proceedings.neurips.cc/paper/2021/file/5bd529d5b07b647a8863cf71e98d651a-Paper.pdf}
}
Full Publication List
Yangyuxuan Kang, Dongqi Cai, Yuyang Liu, Anbang Yao, etc.
In IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025, accepted
Dongqi Cai, YangYuxuan Kang, Anbang Yao, Yurong Chen
In International Conference on Machine Learning (ICML), 2023 [Paper]
Dongqi Cai, Anbang Yao, Yurong Chen
In Advances in Neural Information Processing Systems (NeurIPS), 2021 [Paper]
Zhou Su, Chen Zhu, Yinpeng Dong, Dongqi Cai, Yurong Chen and Jianguo Li
In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), 2018 [Paper]
Ping Hu, Dongqi Cai, Shandong Wang, Anbang Yao, and Yurong Chen
In Proceedings of the 19th ACM International Conference on Multimodal Interaction (ICMI), 2017 [Paper]
Anbang Yao, Dongqi Cai, Ping Hu, Shandong Wang, Liang Sha, and Yurong Chen
In Proceedings of the 18th ACM international conference on multimodal interaction (ICMI), 2016 [Paper]
Dongqi Cai, Fei Su and Zhicheng Zhao
In 22nd International Conference on MultiMedia Modeling (MMM), 2016 [Paper]
Dongqi Cai and Fei Su
In IEEE International Conference on Image Processing (ICIP), 2015 [Paper]
Dongqi Cai, Kai Liu and Fei Su
In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015 [Paper]
Dongqi Cai, Pengyu Li, Fei Su and Zhicheng Zhao
In IEEE Visual Communications and Image Processing Conference (VCIP), 2014 [Paper]
Dongqi Cai and Fei Su
In IEEE International Conference on Network Infrastructure and Digital Content (ICNIDC), 2014 [Paper]
Dongqi Cai and Fang Wei
In IEEE InternationalConference on Network Infrastructure and Digital Content (ICNIDC), 2010 [Paper]